 Why LLMs don’t sound human, strategies to fix it, and real examples.
Why LLMs don’t sound human, strategies to fix it, and real examples.
为什么LLM听起来不像人类,修复它的策略以及真实的例子。
I’ve talked to a lot of people that think it’s obvious when text has been written by LLMs. That’s true for most generated text. However, this can lead to overconfidence in determining if something has been written by AI.
我和很多人谈过,他们认为当文本是由LLM编写时很明显的。对于大多数生成的文本都是如此。但是,这可能会导致在确定某些内容是否由AI编写时过度自信。
It creates a bias towards trusting content that “seems legit.” It may also lead teachers and professors to believe their intuition (or even programs like TurnItIn) will be able to detect LLM-generated content.
它造成了对信任“看似合法”的内容的偏见。这也可能导致教师和教授相信他们的直觉(甚至像TurnItIn这样的程序)将能够检测到LLM生成的内容。
This is a misconception. The reality is that this is a limitation of the prompt. Prompts which generate human-sounding text are feasible to write. I offer examples below, but first let me explain why I believe LLMs have a distinct default tone.
这是一种误解。现实情况是,这是提示的限制。生成人类文本的提示是可行的。我在下面提供示例,但首先让我解释一下为什么我认为LLM具有明显的默认基调。
Why So Serious 为什么这么严重
LLMs use RLHF (Reinforcement Learning from Human Feedback) to improve their responses. They are trained on a diverse range of internet text. They predict what text should come next based on patterns and feedback. Humans are impressed by good vocabulary and academic-sounding output. So it’s natural that the default style of LLMs has migrated towards that.
LLM使用RLHF(来自人类反馈的强化学习)来改善他们的反应。他们接受过各种互联网文本的培训。他们根据模式和反馈预测接下来应该出现什么文本。良好的词汇量和听起来像学术的输出给人类留下了深刻的印象。因此,LLM 的默认样式已向此迁移是很自然的。
Also, academic content tends to be dense with information. When we are testing or chatting with LLMs, we usually want information. This also likely leads to them sounding more academic.
此外,学术内容往往信息密集。当我们与LLM进行测试或聊天时,我们通常需要信息。这也可能导致它们听起来更学术。
Another sign of good writing is not using the same words over and over again. LLMs literally have features which decrease the likelihood of repeating tokens. Humans, on the other hand, tend to use the same words over and over, especially in informal writing.
好写作的另一个标志是不要一遍又一遍地使用相同的单词。LLM从字面上看具有降低重复令牌可能性的功能。另一方面,人类倾向于一遍又一遍地使用相同的单词,尤其是在非正式写作中。
This is why LLMs often sound formal or academic. The training data is skewed towards more formal, information-dense text. This doesn’t mean they can’t generate casual or creative text, it just means they’re less likely to do so unless specifically prompted.
这就是为什么LLM通常听起来正式或学术。训练数据偏向于更正式、信息密集的文本。这并不意味着他们不能生成随意或创造性的文本,只是意味着除非特别提示,否则他们不太可能这样做。
Strategies For Generating Human-like Text
生成类人文本的策略
There are a couple ways to get more authentic sounding output.
有几种方法可以获得更真实的声音输出。
Ask for less formal text directly. Here’s some examples:
直接要求不太正式的文本。以下是一些示例:
- “Write a text message to a friend about (topic)”
“给朋友写一条关于(主题)的短信” - “Write a junior high level paper about (topic). It shouldn’t be well written.”
“写一篇关于(主题)的初中论文。它不应该写得很好。 - “Informally, as if writing on IRC or Reddit, tell me about (topic) but still use good grammar and puctuation.”
“非正式地,就像在IRC或Reddit上写作一样,告诉我(主题),但仍然使用良好的语法和标点符号。
Limit its vocabulary by adding something like this to your prompt:
通过在提示中添加类似以下内容来限制其词汇量:
<prompt>. It should use middle school level vocabulary.
Give it the desired style as context by including a few thousand tokens of the writing style and tone you’d like it to emulate. Example:
通过包含您希望它模仿的写作风格和语气的几千个标记,给它所需的风格作为上下文。例:
Write about <prompt>. It should use my tone and voice.
Here is a sample of my writing so that you can emulate it:
<snippet of your writing>
Utilize presence_penalty or frequency_penalty to increase the chance of repeating words. Let’s assume you’re using OpenAI’s models. If you’re using Simon’s command line tool llm, you would use -o presence_penalty -.8 (or any value between -2 and 0) but you can also pass presence_penalty and frequency_penalty in via the API. Here’s an example using llm command line tool.
利用presence_penalty或frequency_penalty来增加重复单词的机会。假设你使用的是OpenAI的模型。如果您使用的是 Simon 的命令行工具 llm,您将使用 -o presence_penalty -.8 (或 -2 到 0 之间的任何值),但您也可以通过 API 传入 presence_penalty frequency_penalty 。下面是使用命令行工具的示例 llm 。
echo '<prompt>' | llm -o presence_penalty -.8
Put the desired format in the prompt because a middle school essay, for example, will have a rigid Introduction-Arguments-Conclusion structure. By limiting its creativity to the skill level of the desired output, you can force it to seem more like the intended writer. This can be extrapolated to other structures. Example:
将所需的格式放在提示中,因为例如,中学论文将具有严格的引言-论点-结论结构。通过将其创造力限制在所需输出的技能水平上,您可以强制它看起来更像预期的作家。这可以外推到其他结构。例:
<prompt> it should be 5 paragraphs. 1 intro where it introduces
the 3 ideas of the middle 3 paragraphs. and then 1 conclusion
paragraph that also mentions the 3 main ideas.
Full Examples With Real Output
具有实际输出的完整示例
Note: If you can’t read theses, right click on the image and choose “Open in New Tab” to view them easier.
注意:如果您无法阅读论文,请右键单击图像并选择“在新选项卡中打开”以更轻松地查看它们。
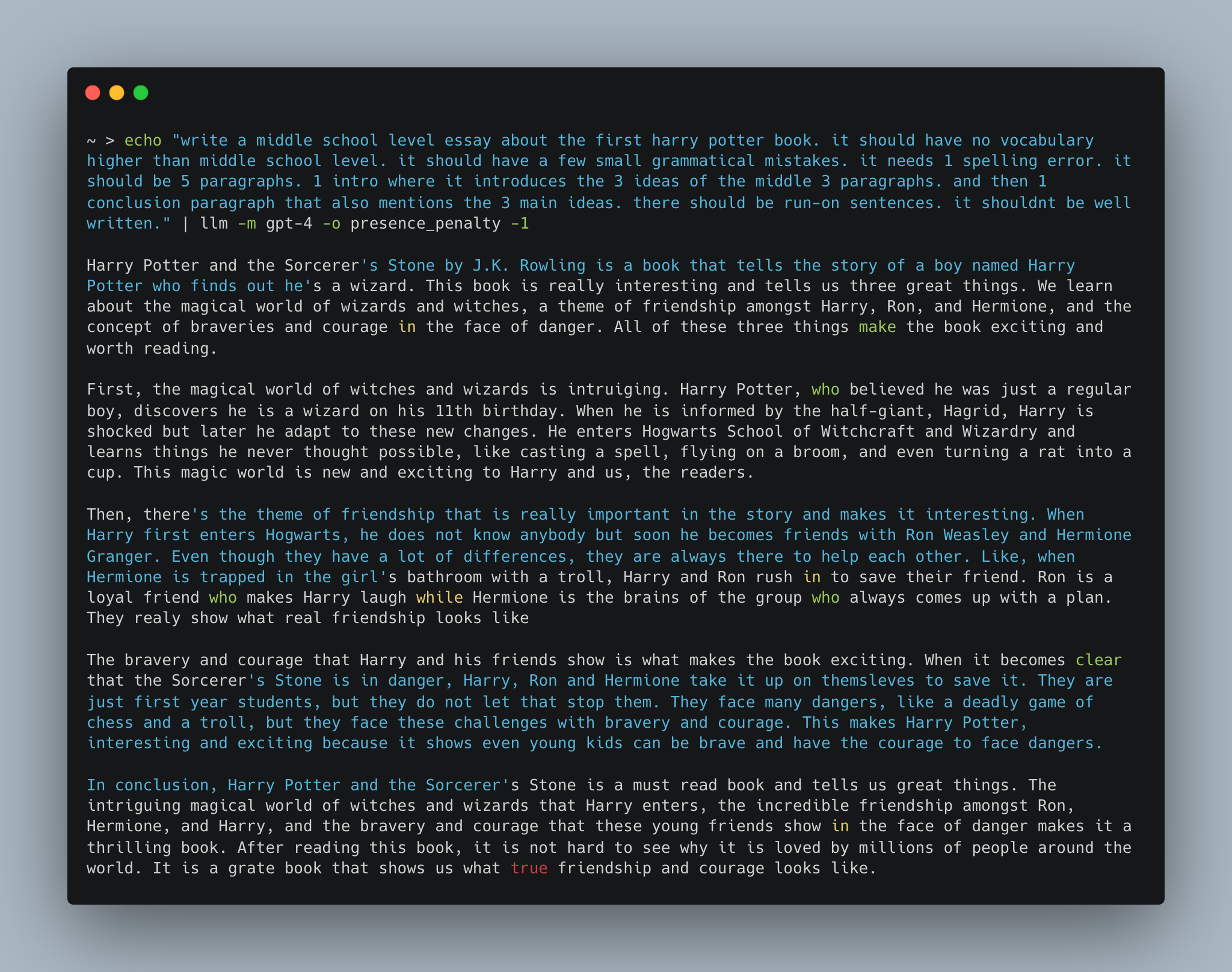
Harry Potter Paper Example
哈利波特纸示例
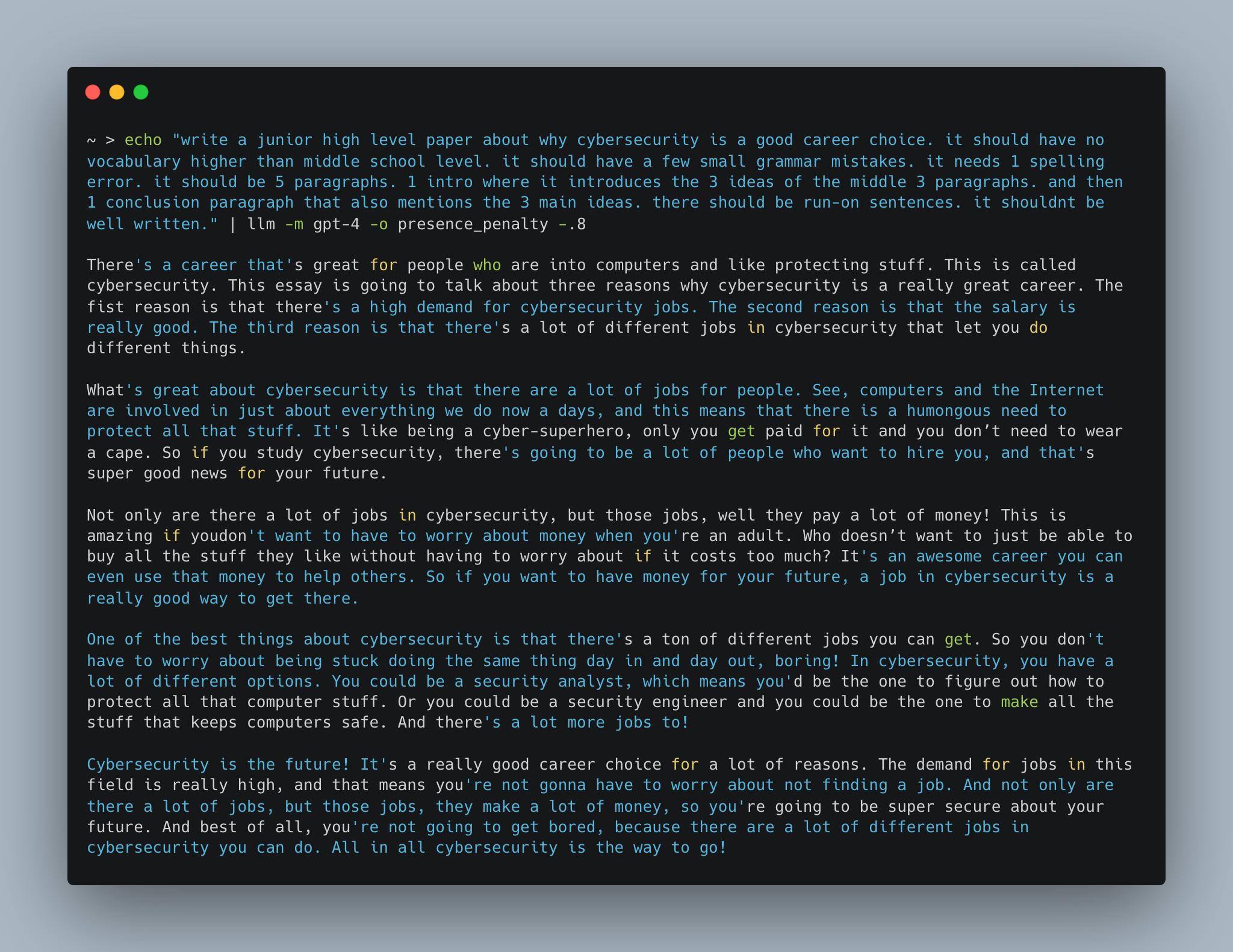
Cybersecurity Career Essay Example
网络安全职业论文示例
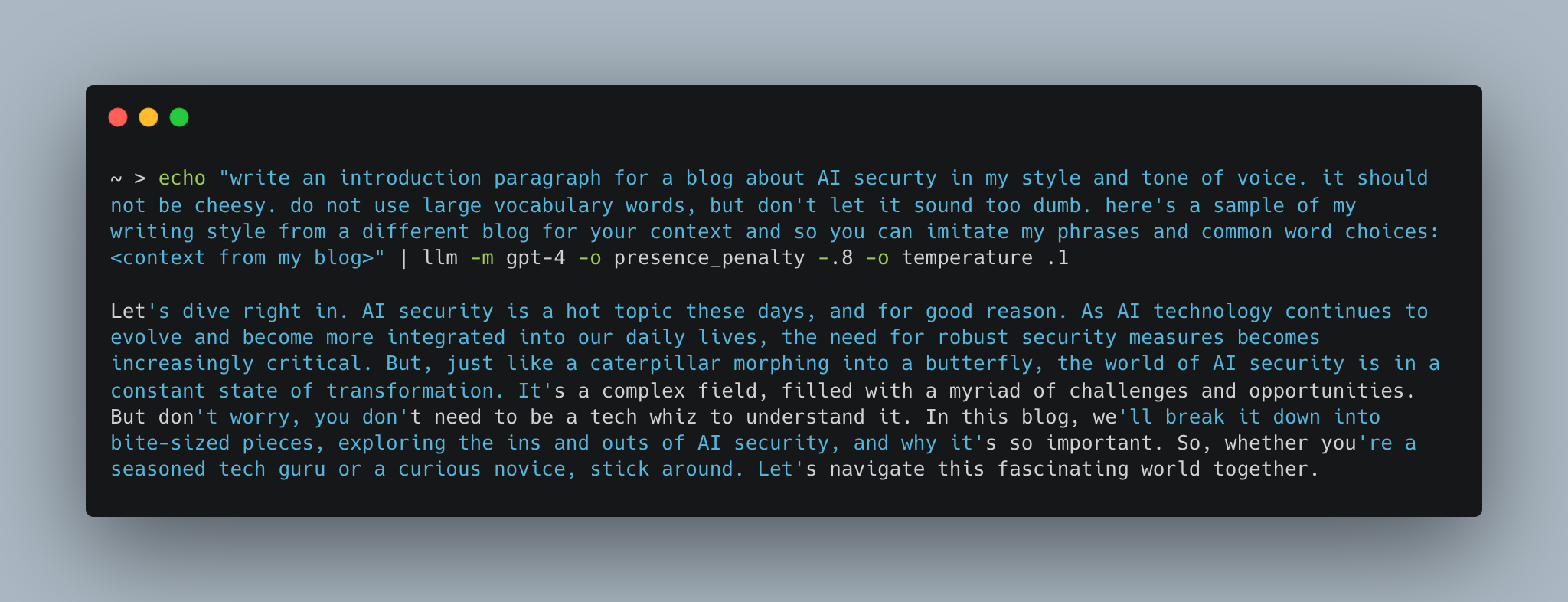
New Blog Post Introduction Example
新博客文章介绍示例
Conclusion 结论
While it’s true that LLM-generated text often has a distinctive style, it’s not because LLMs are inherently formal or uncreative. It’s a reflection of the data they were trained on and the way they were prompted. With the right prompt, I believe LLMs can generate text that is indistinguishable from human-written text.
虽然LLM生成的文本通常具有独特的风格,但这并不是因为LLM本质上是正式的或没有创意的。这反映了他们接受训练的数据以及提示他们的方式。通过正确的提示,我相信LLM可以生成与人类编写的文本无法区分的文本。