出题人の碎碎念
打了两年HackerGame之后从USTC毕业了,然后今年第一次参加出题,整了两道比较传统的密码题:不可加密的异世界(200+200+250)和置换魔群(200+200+300),大概是math分类里面最接近传统CTF的CRYPTO分类的题了,因为很早就出好了,所以文案稍微整了整活:不可加密的异世界的flag和文案是魔改自经典韩剧《鬼怪》的经典台词(只不过好像不太明显orz);另外一题置换魔群是看了有限单群的分类历史后,改的文案,最令我叹为观止的是数学家们能证明宇宙里面存在的单群结构是可分类的,以及魔群月光猜想和其衍生的伴影月光猜想与弦论之间千丝万缕的联系。
回到这两道题本身,这两道题都不算很难,特别是前两问都是送分的,其实出完题目再看,不可加密的异世界前面两问完全可以写成一问的,因为完全卡不住人,这算是出题人的一个失误;另外第三问逆CRC这题,还是出的简单了,导致了很多非预期,如果对输入消息的明文加一些限制——前后缀、字符集,会有趣很多。置换魔群这题第三问,我出题时候的贪心策略的次优解相比最优解还是差了1~2个数量级,所以这题被很多OI爷们打穿了。但是总体而言,出题体验还是蛮好的,明年再见。
后面大概讲一讲不可加密的异世界、置换魔群两题的预期解,所有题目的官方题解参考:hackergame2022-writeups。
碎碎念:关于魔群和群论的发展
出到置换魔群是因为出题人最近看了看有限单群的分类历史,觉得很有意义,捣鼓了一阵子发现最好出题的还是置换群——直观、并且容易实现,另一方面就是任何有限群都可以嵌入到某个置换群上,所以置换群可以体现很多典型的群结构。
群论是数学对现实的抽象,比如人类发明数字,实际上是把一切的:三颗树、三块钱、三朵云全部抽象为3;定义的加减乘除都来自于现实:三棵树砍了一棵树就变成了两颗树,这就是 3-2=1 的实际意义。从根本上来说,3-1=2 这个等式这体现了宇宙本身的逻辑,即使我们遇见了某个外星文明,我们用某种方式表达出这样的一个数学等式,他们也会认同这个结论。数字符号的发明可以说是人类群论发展的起源,之后人们又根据对称性、置换等等抽象出一系列现实中存在的群。宇宙是逻辑的必然,只是人类对这个终极逻辑的了解还只是冰山一角。
现代群论的一个重大进展是有限单群的分类,有限单群,英文名叫“finite simple group”,从名字就能猜出来它的性质了:有限单群,它没有内部结构,不能分解成更基本的群的直乘形式,并且元素个数也是有限的。也许你会认为宇宙无穷无尽,从这里面可以抽象出无数种有限单群结构吧,但是数学家们用了100年、近10000页期刊告诉我们整个宇宙上的有限单群只有下面几类:素数阶循环群、置换群(5阶以上)、16种李型群、26种散在单群!在2012年绘制出了类似化学上的元素周期表(图源)。巧合的是,有限单群分为18个族类,这与化学周期表的18族刚刚好相等,但是有限单群更复杂的是它还存在26种散在单群,也被称为孤儿群,因为它们就像被宇宙抛弃了一样,无法归类,其中最大的散在单群就是魔群(大魔群)。元素周期表告诉我们宇宙的粒子种类是有限的(目前是),而有限单群分类定理证明了,这个宇宙的群结构居然也是有限的,并且结果相当简洁,这让人不禁怀疑宇宙是不是经过精心设计的一个世界——宇宙存在着其最终极的逻辑,而这个逻辑衍生了我们整个世界。
另外一个很有意思的点就是,群论在某种程度上可以统一当今科学的研究分支。前面说到过,群论是数学对现实事物结构的抽象,比如物品的对称性,因此由群论引申出很多的物理上的定理都令人拍案叫绝。比如诺特定理——理论物理的中心结果之一:每个连续的对称性都有着相应的守恒定理,浅显地说,物理上的能量守恒定律、动量守恒定律都对应了一个群论上抽象出来的群。这些普适的物理定理居然存在群的结构里面!这就是群论的魅力所在:群结构从实际事物中抽象出来,但却能揭示更深层次的宇宙逻辑。
也许从上面群论的分类结果看来,宇宙的逻辑好像也没有那么复杂了?但是我们前面提到过,有限单群有基本的18个族群,但还存在着其他26个散在的单群,就好像宇宙是随意设计的一样,这26个群与其他所有群都截然不同。单独拆开一个个群去看,你就会发现宇宙也远远没有那么简单。难以想象的是宇宙存在一个包含808017424794512875886459904961710757005754368000000000个元素的大魔群——散在单群里面最大的群。这个数字比地球上所有原子的1000倍还要多,更加难以想象的是数学家们是怎么构造出这样一个复杂的单群的。
为什么要特别提这样一个数字呢?因为这个数字与我们的宇宙息息相关,是很特别的一个数字,这就要提到现代赫赫有名的“魔群月光猜想”,它揭示着“魔群也许就代表着我们这个宇宙终极的对称性”。魔群把群论与完全不相干的另一个数学领域里的J函数关联了起来:汤普森教授发现J函数的傅里叶展开系数与魔群的阶息息相关,某项系数即为魔群阶的最小素因子加一,并且之后又发现了更多的“巧合”,但是数学家们难以发现这种巧合的实际意义。直到魔群的结构与研究宇宙起源的弦理论关联了起来:上世界90年代弦论物理学家博赫兹通过一个特定的弦理论模型让魔群、J函数、弦论完美结合了起来。在这个弦理论模型中,J函数和魔群同时起到了作用——J函数的系数决定着弦在每个能级(energy level)上振动方式的数目,而魔群则约束着模型在这些能级上的对称性。
魔群月光猜想的证实揭示了一个很重要的事情:这些散在单群可不是宇宙随意生成的,它可以体现在宇宙的具体事物上:在“魔群月光”观测到的弦理论中指出,194个可被自然归类的普通群对应着194种不同类型的黑洞!所以,群论、J函数、弦论、黑洞,这些看似不相干的东西,本质上是联系在一起的,即使是魔群这样复杂的结构里,却也惊人地体现了宇宙的统一性。
如今,现代数学、物理学(尤其是弦论物理学)的一个热点聚焦到了宇宙里面孤零零不成族群的26个散在单群上面,由魔群月光猜想引申到了其他散在单群的“伴影月光猜想”被众多科学家们研究,这些猜想的一系列数学证据在2015年arxiv.org上发表,需要完全研究出这一系列散在单群的核心内涵,可能还需要很长的一段路程,但可以肯定地是这些群的研究会让人类对宇宙的终极逻辑有更进一步的了解。
不可加密的异世界
解题思路
这题的出题的思路就是通过一些小trick使得加密后的密文与明文相同。前面两道题的预期解都是利用CBC模式下的IV的冗余,不需要任何爆破,就可以指定任意一个密文分组的值为我们预期的值,详情参见第二部分。
最后一问主要是两个点:crc类哈希都是可逆的以及DES的弱密钥;做到了第三问,你会发现前面两问好像DES用不用都一样,DES也就是为了第三问加进来的,AES是目前最流行的对称加密体制,没有任何已知的有效攻击;而DES是存在诸多问题的,差分攻击、彩虹表、弱密钥等等。而最后一问我们是要求加密两次恢复到原明文,这比加密一次恢复到原明文的条件更弱,因此只要使用DES的弱密钥(在Feistel结构下可以直接用该加密密钥作为解密密钥,不需要逆序使用子密钥),就可以两次加密(实际上等价于加密+解密)恢复明文。由于crc哈希是可逆的(见第三节),我们就可以直接把一个DES弱密钥当哈希逆向得到我们的消息,提交该消息即可。
完整题解和 exp 见附件 unencryptable-exp.ipynb。
非预期
0xffffffffffffffffffffffffffffffff是一个解,因为这玩意crc128出来就是它本身,并且这是一个des弱密钥。(issue)- python居然有轮子:crcsolver(来自榜一的writeup)。
CBC模式指定任意密文分组
CBC模式的字节反转攻击算是CTF中老生常谈的考点了,这里也是稍微利用了一下CBC的模式特征:
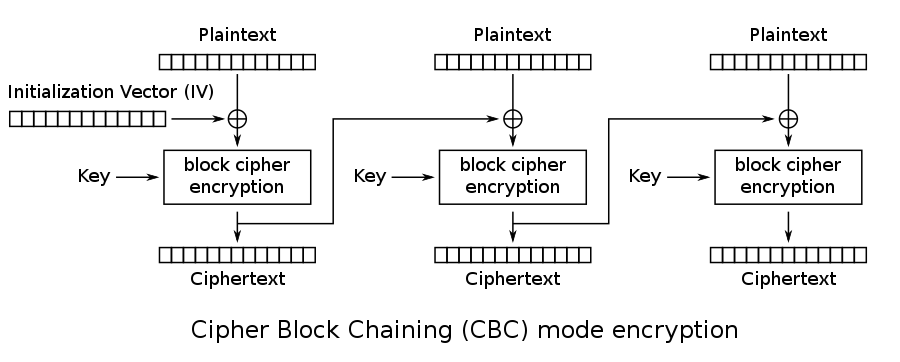
如果在CBC分组加密模式下,我们可以选择IV并且已知Key的值的话,那么IV这16个字节的冗余可以转移到任意一个密文分组:也就是说我们可以任意指定一个密文分组的值,从而反推出所有密文分组的值以及IV的值。特别地,当明文长度就是一个分组时,我们可以控制整个密文的值。原理如下, 假设我们指定密文分组 Ci 为原来的明文 mi:
- Ci之后的密文:按CBC模式加密即可,初始IV就是 Ci, 密钥为Key(这部分按标准CBC加密即可)。
- Ci之前的密文: Ci−1=Dec(Ci)⊕Mi,以此类推,直到IV的值确定。
第一问根据提示,我们只要控制明文长度不超过16字节即可,因此随便输入单个字母,然后往前面推一步,就得到了IV值,第二问就是第一问的一个拓展,我们每次指定一个分组加密后为明文即可,主要的攻击代码写出来如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
from Crypto.Util.number import * from Crypto.Cipher import AES import os block_size=16 key_size=16 def pad(msg:bytes,block_size = 16): n = AES.block_size - len(msg) % AES.block_size return msg + bytes([n]) * n def unpad(msg, block_size = 16): return msg[: -msg[-1]] def xor(b1:bytes, b2:bytes): return bytes([x ^^ y for x, y in zip(b1, b2)]) def split_block(text:bytes): assert len(text)%block_size==0,'Invalid length' return [text[i*block_size:(i+1)*block_size] for i in range(len(text)//block_size)] def AES_CBC_chosen_ciphertext(AES_key:bytes,plaintext:bytes,chosen_ciphertext:bytes,pos=None): # pos = None the iv will be set as chosen ciphertext # pos = -1 : the last block will be set as ciphertext # pos = i : the ith (from 0) block will be set as ciphertext if pos==None: iv=chosen_ciphertext aes_cbc=AES.new(AES_key,AES.MODE_CBC,iv) return iv,aes_cbc.encrypt(msg) iv=os.urandom(block_size) aes_cbc=AES.new(AES_key,AES.MODE_CBC,iv) aes_ecb=AES.new(AES_key,AES.MODE_ECB) cipher=aes_cbc.encrypt(msg) msg_blocks=split_block(msg) cipher_blocks=split_block(cipher) cipher_blocks[pos]=chosen_ciphertext for i in range(pos-1,-1,-1): cipher_blocks[i]=xor(aes_ecb.decrypt(cipher_blocks[i+1]),msg_blocks[i+1]) iv=xor(aes_ecb.decrypt(cipher_blocks[0]),msg_blocks[0]) for i in range(pos+1,len(cipher_blocks)): cipher_blocks[i]=aes_ecb.encrypt(xor(cipher_blocks[i-1],msg_blocks[i])) return iv, b"".join(cipher_blocks) |
逆CRC128哈希
Hacker Game之前也出过crc128类似的题:HakcerGame2020中间人,更进一步可以找到TCTF的这道题:fixed ponit。无一例外,它们都利用了crc128的仿射函数性质:Affine Function in GF(2128),其中TCFT这题的writeup还介绍了基于多项式的crc的表示方式,这个方式也可以直接求逆,这里介绍另外一种用矩阵的方式写出crc的表达式。crc仿射函数最容易验证的性质就是: crc(Δ⊕a)⊕crc(Δ⊕b)=const∀Δ. 也就是说只要两个明文的差分是一样的,那么它们crc哈希后的差分就是一个固定值。这个固定值是可以写出来的,定义 _crc(x)=crc(x)⊕crc(0l),其中 0l代表与x等长的"\x00"字节流。对于任意等长的输入就有:
其中 ⊕ 等价于 GF(2)k(∀k∈Z) 上的加法,所以(1)式在 GF(2) 上可记为:
有了这个性质,对于GF(2) 上的128维的向量空间,取一组基底如下: vi=(0,..,1,…,0) , i∈1,2,3,…,128,第i个位置为1其余均为0的标准正交基,我们记这一组标准正交基的 _crc 哈希值的对应的向量为,Vi=_crc(vi)i∈{1,2,3,...,128} ,用 Vi 构建一个在 GF(2) 上的128×128的矩阵:
从上面我们就得到了定长为128比特的输入做crc哈希时在 GF(2) 上的等价矩阵表示(Affine Function)(其他长度的输入换一下矩阵M和 crc(0l) 的值即可), 为了和代码保持一致,我们把 MT 再转置回来:
有了上面的矩阵表示,给定crc128的值,求它对应的一个明文,只需要解一个在GF(2)上的方程组即可 xT=M−1∗(crc(x)T+C) ,这样我们就实现了一个完整的crc_128_reverse函数,这是最基础版本的推导,但是解决这题就够用了。一个简单的sage demo如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
def crc128(data, poly=0x883ddfe55bba9af41f47bd6e0b0d8f8f): crc = (1 << 128) - 1 for b in data: crc ^^= b for _ in range(8): crc = (crc >> 1) ^^ (poly & -(crc & 1)) return crc ^^ ((1 << 128) - 1) def equivalent_affine_crc(crc = crc128, crc_bits = 128, target_bytes = 16): zero_crc = crc(target_bytes*b"\x00") target_bits = 8 * target_bytes v2n = lambda v: int(''.join(map(str, v)), 2) n2v = lambda n: vector(GF(2), bin(n)[2:].zfill(crc_bits)) # n2v_t = lambda n: vector(GF(2), bin(n)[2:].zfill(target_bits)) Affine_Matrix = [] for i in range(target_bits): v = vector(GF(2), (j == i for j in range(target_bits))) value = crc(long_to_bytes(v2n(v),target_bytes)) ^^ zero_crc Affine_Matrix.append(n2v(value)) # crc affine function: crc_128(x) = M*x+ C return matrix(GF(2),Affine_Matrix).transpose(), n2v(zero_crc) def crc_128_reverse(crc_value): M , C = equivalent_affine_crc() # crc affine function: crc_128(x) = M*x+ C v2n = lambda v: int(''.join(map(str, v)), 2) n2v = lambda n: vector(GF(2), bin(n)[2:].zfill(128)) res = M.solve_right(n2v(crc_value)+C) return long_to_bytes(v2n(res),16) |
置换魔群
出题想法
置换群是结构很有趣的一个群,An的最大素数阶子群也就是n以内的最大素数,如果我们要构造求解离散对数困难的置换群An,按照一般的安全性需要,n必须要大于2160,想要无压缩的表示这个群上面的元素,需要至少2319比特,这导致一般可存储的置换群An上的子群都是光滑的,也就是离散对数求解简单的,并且由于置换群的标准形式特别容易看出来离散对数的解(真”看出来”),用这个群来阐述光滑阶群的Pohlig Hellman离散对数求解算法就特别直观。所以这题前面两问有CTF经验的大手子们理解理解题意都能秒了,甚至熟悉sage接口的话,可以直接用sagemath上的SymmetricGroup/PermutationGroup类和discrete_log之类的轮子直接求离散对数,因为我自己用python写的permutation_group类是直接仿照SymmetricGroup来写的,所以要改的地方几乎没有。写代码的时候把元素的order函数都写了,这样的话,第一题就完全是送分的题。
第三问是开放式的一题,这一问的思路很清晰:找到两个 An 上的元素,使得它们阶的最大公倍数最大MAXg1,g2∈Anlcm(g1.order(),g2.order()),如果只有一个元素,那就是求 An 上的最大阶 f(n) ,这个问题是有专门研究过的,称为Landau’s function,详细的研究可以参考A000793,Landau’s function for one million billions,当然,这个问题摊开来就是一个动态规划的问题(01背包)。由于网上都有现成的脚本和结果,这里直接出单个元素形式的解法就可以Google做出来,所以放弃了这么出题。但是,如果扩展到两个元素,我在网上也没有找到确定性的研究结论,因此题目里面给的界只是出题人用贪心算法和动态规划求解出来的一个最大界(肯定不是理论上的最大上界),写writeup的时候又把这个界扩大了一点,如果谁研究出了更大的上界欢迎和我交流讨论。
附注:经过企鹅拼盘(这题用的就是 A15 交错群)出题人的提醒后发现题目文案有些数学上的不严谨,全程提的都是置换群,而没有交错群,交错群是置换群里面所有偶置换的形成的子群,元素个数为: n!2 ;由于出题人没有全文替换之前写的置乱、交错等,导致部分叙述出现了交错群/置乱群, An 一般表示交错群, Sn,Pn 都可以用来表示该题的置换群。 最后,感谢zzh、djh、tky等学长们对于本题出题的意见和帮助。
解题思路
第一题的RSA,只要你对群的阶有一个基本的了解,这题就很简单了,我们加密了一个置换g: c=ge,类比RSA,对应的私钥就很容易算了: d=inverse(e,g.order()),或者求 e=65537模n!的逆也可以,总之:
第二题就是求解离散对数了,本来想糊一个DH密钥的标准交换过程,最后还是直接搞dlp。由于置换群的光滑性质,就可以直接用sage的 discrete_log 出了(盲猜多数解法都会用sage的轮子直接跑了),由于置换群特别容易分解为不相关的子群(子置换),所以Pohlig Hellman光滑阶离散对数算法在置换群上特别直观,怎么自己写轮子参考第三节、代码参考纯python写的exp。
第三题是开放式的一题(因为出题人也没找到最大的上界,雾),最后一节详细介绍了题目里最大阶的贪心构造方法,出题人写writeup的时候又想到了更直观的想法,求解两个元素联合起来的最大阶,只需要在不改变物品的情况下把原来背包问题的容量扩展到 2n即可,之后对阶O素因子分解得到的子集,求解一个approximate subset sum,目标和为 n,由此得到两个 O1,O2作为两个生成元的阶,该方法比我之前得到的最大上界平均大了一个数量级(1~100倍)。
纯 Python 解法(完善了 permutation group 类)参考 python-exp,SageMath 脚本参考 sage-exp。
置换群上的Pohlig Hellman算法
我们首先来看A5上简单的例子, A=(1,3)(2,4,5),对于位置不变的置换,我们将缺省,比如单位置换(不变置换): A=(1)(2)(3)(4)(5)=(),考虑e = 1,2,3,4,5,6
我们单独观察单个的小置换可以发现,(1,3)的周期为2,(2,4,5)的周期为3,所以A的阶是6:
- 对于初始的A,1置换到3, A2置换就变成1置换3再置换到1,也即是1置换到1,周而复始;
- 对于初始的A,2置换到4, A2置换就变成2置换4再置换到5,也就是2置换到5, A3就变成2置换到2,周而复始。
因此,一般性的结论就是,我们考虑A每个长度为 li 小置换 (x1,x2,...,xli) , Ae 结果为:(x1,xj,...),则 e≡j−1modli ,对于每个小置换我们都能得到这样一个式子,最后对所有关于 li 的方程用中国剩余定理求解出来,我们就得到了 emodlcm(l1,l2,..,lk)=order(g),也就是我们能够得到的关于e的最大的信息量了,如果 e>order(g) ,我们是没法完全恢复出e的。
上面的方法也就是Pohlig Hellman算法的核心思想,不过在一般有限域 Zp 上面,子群(相当于A里面的小置换)是不好区分的,需要我们自己去构造。详细算法可以参考wiki。
当然,由于题目里面的每个小子群的阶不超过2000,因此直接对每一个小子群进行打表,计算下面的式子:
1
|
[(e, sub_element**e) for sub_element in g.standard_tuple for e in range(len(sub_element))]
|
这样把结果里面的y对应的小置换直接查表得到对应的e即可,也就得到了 x≡emodsuborder。
An上的最大阶元素(Two-Generator)
Landau’s function
考虑 An上一个置乱的阶,从互不相关小置乱的乘积的标准形式来看是最清晰的,我们只考虑小置乱的长度,记置乱A的长度数组为: [l1,l2,..,lk],那么求 An 的最大置乱阶的问题就等价于下面问题(lcm:最大公倍数):
最优解有下面两种性质几种情况:
- li 是不是非素数的次幂之外的合数,否则: li=a∗b(非平凡分解),由于 ba,ab≥a∗b,a,b>=2 恒成立,并且在于其他数做LCM时, ab,ba 之一的结果肯定不小于 a∗b 的结果,因此最优解里面一定不存在上述合数。
- Landu(n) 一定可以表示为 Landu(n)=MAXpk<nlcm(pk,Landu(n−pk)) (最优子结构)
有了上面的结论就可以类似01背包问题愉快地动态规划了,背包的容量是n,里面可以塞的东西就是小于n的所有素数次幂, [p,p2,..,pk]被归为一组,并且每一组内只能取一个元素。这样就可以用动态规划一次性解出所有小于等于n的最大阶。这是A000793上给出的python动态规划代码:
1 2 3 4 5 6 7 8 9 10 11 |
def aupton(N): # compute terms a(0)..a(N) V = [1 for j in range(N+1)] for i in primerange(2, N+1): for j in range(N, i-1, -1): hi = V[j] pp = i while pp <= j: hi = max((pp if j==pp else V[j-pp]*pp), hi) pp *= i V[j] = hi return V |
贪婪策略
题目中上界的的生成方法,思路就是不管三七二十一,先产生 An 上的一个最大阶为 O1 的元素 g1 ,由于 g1用到了n以内的某些素数、素数的次幂,所以我们第二次找最大阶元素的时候,需要重新更新一个物品(素数、素数次幂)的价值(权重),价值的更新策略如下:如果 O1 里面包含了素因子 pk (k取最大的那个),那么:
- ∀ i≤k:Value(pi)=1
- ∀ i>k:Value(pi)=pi−k
更新物品价值后,再求解一次背包问题,得到第二个元素的最大阶 O2 ,根据 O2 产生基底 g2。纯粹的贪婪策略,最后为了防止直接分解这个上界得到泄露结果,最终的bound经过下面盲化处理:bound = lcm(O1,O2) + randint(1, lcm(O1,O2)//100)。连续通过15轮的概率是 0.9915≈0.87 。
代码如下(之前用c写的,抄过来有点丑)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# sage 9.5 # For python you can use the `factorint` from sympy instead of `factor` # from sympy import factorint # factor = lambda x: list(factorint(x).items()) from math import sqrt,gcd from Crypto.Util.number import * from sympy import nextprime def PrimeN(n): a = [0]*(n+1) a[0] = a[1] = 0 for i in range(2,n+1): a[i] = 1 for i in range(2,int(sqrt(n)+1)): mul = 2 if (a[i] == 0): continue while (i * mul <= n): a[i * mul] = 0 mul+=1 return a def max_order_element_combine(n,nums=1): #MX = [1]*(n+1) prime = PrimeN(n) prime_pows = {} # init item values for i in range(n,-1,-1): if not prime[i]:continue k = i*i prime_pows.setdefault(i,i) while (k <= n): prime[i]+=1 prime_pows.setdefault(k,k) k *= i res = [] # store the results for _ in range(nums): MX = [1]*(n+1) for i in range(2,n+1): if not prime[i]:continue for j in range(n,1,-1): temp = i for k in range(1,prime[i]+1): if (j - temp >= 0 and MX[j] < MX[j - temp] * prime_pows[temp]): MX[j] = MX[j - temp] * prime_pows[temp] temp *= i res.append(MX[-1]) res_facts = factor(res[-1]) # renew the item weights for f in res_facts: p_f =f[0]**f[1] j = f[0] while j < n: if j <= p_f: prime_pows[j] = 1 else: prime_pows[j] = min(j//p_f,prime_pows[j]) j*=f[0] return res |
背包扩容策略
思路就是扩容背包,不扩大物品(素数幂)的选择范围;我们把背包容量扩大两倍,由此得到的最大阶O以及其标准素因子分解 num_set=[pk11,...,pkll] ,肯定有 : ∑ipkii≤2∗and ∀ pkii≤n 成立。之后我们以 num_set 为总的数集,以 n为目标和,求解最接近子集和问题,如果基于此对 num_set 划分的两个子集和都小于等于n,就可以构造符合条件的两个基底了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# sage 9.5 # python version in python exp def aupton_2(N): # compute terms a(0)..a(N) V = [1 for j in range(2*N+1)] for i in primerange(2, N+1): for j in range(2*N, i-1, -1): hi = V[j] pp = i while pp <= j: hi = max((pp if j==pp else V[j-pp]*pp), hi) pp *= i V[j] = hi return V ''' Wikipedia subset sum approximation algorithm http://en.wikipedia.org/wiki/Subset_sum_problem#Polynomial_time_approximate_algorithm from https://github.com/saltycrane/subset-sum/blob/master/subsetsum/wikipedia.py ''' import operator def approx_with_accounting_and_duplicates(x_list,s): c = .01 # fraction error (constant) N = len(x_list) # number of values S = [(0, [])] for x in sorted(x_list): T = [] for y, y_list in S: T.append((x + y, y_list + [x])) U = T + S U = sorted(U, key=operator.itemgetter(0)) y, y_list = U[0] S = [(y, y_list)] for z, z_list in U: lower_bound = (float(y) + c * float(s) / float(N)) if lower_bound < z <= s: y = z S.append((z, z_list)) return sort_by_col(S, 0)[-1] def split_2n(n,order): num_set = set([p^e for p,e in factor(order)]) target_sum = n sum1,prime_list1 = approx_with_accounting_and_duplicates(num_set,target_sum) prime_list2 = num_set - set(prime_list1) sum2 = sum(prime_list2) if sum1 <= target_sum and sum2 <= target_sum: return prod(prime_list1),prod(prime_list2) def Landu_expand(n): order = aupton_2(n)[-1] return split_2n(n,order) |
原文始发于tl2cents:HackerGame 2022 出题记