
赛题要求
根据给出的包含黑白域名的域名集(规模约为 27 万),对网站进行分类(涉赌、涉黄、涉诈),并根据网站之间的关联关系进行黑产团伙分析,同时根据域名排名以及访问量评估黑产团伙规模以及活跃度。
数据准备
因为是大数据比赛,所以数据的搜集和建立就变得很重要。
我们使用现有的轮子 dns-crawler 抓取和域名有关的信息,包括 DNS、HTTP、HTTPS 等相关信息,还使用了 Playwright + Chromium 进行了动态渲染和记录,并使用多进程并行运行,加快获取原始数据信息的速度。因为都是些基础工作,在此就不过多描述,具体实现可看代码。
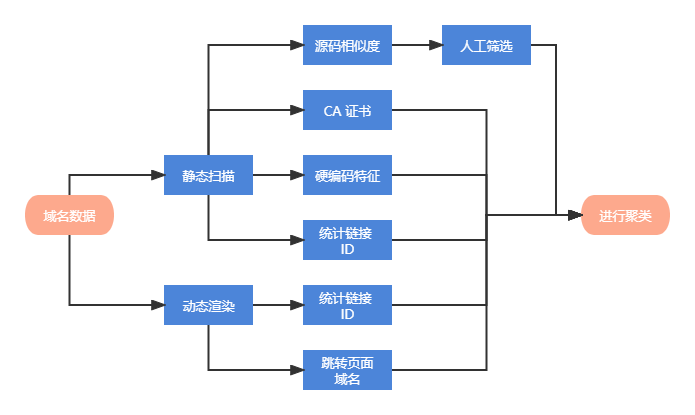
关联图
对于黑产团伙的分析,我们采用最基础的图模型进行分析,域名为结点,域名之间的关系为边。具体实现中为了加快处理速度,我们使用并查集来维护属于同个子图的所有节点的集合。边的构成主要从以下 7 个方面,按照关联性从强到弱排序如下:
- 搜集支持 HTTPS 访问的域名所使用的 CA 证书,如果有两个域名出现在同一个 CA 证书的 Alternaive Name 中,则在两个对应结点之间连边
- 通过正则匹配提取 HTML 中硬编码的 IP 地址和邮箱地址,如果有两个域名的 HTML 源码中出现了相同的元素,则在两个对应结点之间连边
- 通过正则匹配提取网站统计链接,根据链接中的 ID 来进行判断,如果有两个域名的 HTML 源码中出现了相同的统计链接 ID,则在两个对应结点之间连边
- 动态加载并渲染页面,如果有两个域名跳转后的 URL 一致,则在两个对应结点之间连边
- 动态加载并渲染页面,如果有两个域名在加载时请求了相同的统计链接,则在两个对应结点之间连边
- 属于同个黑产集团的域名 HTML 源码可能会有一些相同的特征,需要人工提取,如果有两个域名的 HTML 源码存在相同的人工提取特征,则在两个对应结点之间连边
- 如果有两个域名的 HTML 源码相似度极高,则在两个对应结点之间连边
为了进行上述关系分析,我们需要获得域名的 HTTPS CA 证书、HTML 源码、动态加载并渲染时请求的 URL 和加载完成后的 iframe 框架。
部分人工干预
判断关联种类的强弱是基于人工干预的比例来决定的。越强的关联性需要越少的人工干预(例如 CA Alternative Name),而越弱的关联性则需要越多的人工干预。例如某些域名在过期后会跳转到域名服务商,如果不排除该特殊情况则会错误地将这一类本没有关系的域名归为一类。如果根据 HTML 源码相似度极高这个评价标准进行聚类,误判的可能性很高,因为不同黑产可能会使用同一套页面模板,同时有些域名返回的 404 页面也高度相似(这取决于服务器使用了什么 Web Server)。对于动态渲染加载的数据,我们经过人工筛选去掉了一些因过期而跳转到域名服务商的域名。不将这些数据排除的话,这些域名就会被错误地聚为一类,哪怕这些域名之间根本没有关联。
虽然根据内容相似度来判断会造成大量误判错判,但这不妨碍我们利用相似度数据通过人工的方法去鉴别某些域名是否属于同个黑产。可以说,内容相似度的引入大大减轻了人工判断的工作量,我们在人工干预中主要依据的也是相似度聚类的结果。
对于网站内容的判断,由于我们事前已经进行了源码相似度的聚类,对于相似度极高的同类内容,其内容也只可能是相同类型的,因此只需要人工对于每个聚类都打上标签即可,仅需少量的工作量。
源码相似度聚类算法
我们设计了一套判断 HTML 源码相似度的算法:首先将 HTML 源码中的非 ASCII 码字符、字母、数字和某些转义字符组合 &#; 过滤去除,然后两两计算之间的最长公共子序列长度。计算单次最长公共子序列的 DP 算法的最坏时间复杂度为 O(L2),两两之间都进行计算的最坏时间复杂度为 O(N2L2),其中 N 为域名集规模,L 为经过过滤后的 HTML 源码的长度。
我们意识到该算法的时间复杂度意味着想要在短时间内跑完整一轮是不现实的,为此我们还引入了一些优化。我们将数值性问题改为判定性问题,不再考虑最长公共子序列长度的数值本身,实现上我们只关心有哪些域名对同时满足了「最长公共子序列占比超过 90%」「最长公共子序列和原串相差不超过 100 个字符」这两个条件,若同时满足则表明该域名对的两个域名源码相似度极高。我们通过预处理出过滤后的长度,并进行一轮桶排序,使得某些长度差距过大的域名对不会参与到计算中来,需要计算的域名对的数量规模远远小于 O(N2)。我们还对最长公共子序列算法进行了改进,当在算法运行中能够判断条件必定不满足的时候提前退出算法,使得算法最坏时间复杂度下降到 O(100N),并使用 C++ 进行算法编写(Python 实在是太慢了),结合多进程进行计算。
计算结果中前 10 多的聚类如下表所示:
| 数量 | 源码平均长度 | 典型域名 |
|---|---|---|
| 21933 | 660 | fnxs**.com |
| 7171 | 2446 | trzg**.cn |
| 2943 | 783 | hfpingg**.com |
| 2442 | 4250 | arrive-in-sty**.com |
| 2048 | 17386 | sweptawa**.com |
| 2043 | 56306 | ule1**.com |
| 1823 | 106789 | qm87**.com |
| 1516 | 791 | qqsi**.com |
| 1497 | 31459 | 44447**.com |
| 1477 | 28708 | hfrs**.com |
分析结果
经过少量的人工干预,我们最终找出了 17 个黑产家族(这里的找出指的是发现了 90% 的家族域名),其余家族也或多或少被找到,最后得分 77.7055555436,排名第一。
同时我们还根据聚类的结果和分数反推,发现若干个在答案中的黑产家族居然互相有关联。通过和出题人沟通,我们成功让答案中的家族数量减少了 4 个,即原本答案中的五个家族被合并成了一个家族。同时我们也找到了若干个域名数量在下发的数据集中上千的黑产家族,并且这些家族并未出现在答案中,说明我们的方案对未知的数据集已经有了自动分析的能力。
为了解释聚类的结果,我们还实现了一个域名关系分析器,用来分析两个域名之间的关系链,方便人工判断并解释家族合并的情况。域名关系分析器使用了层次优先搜索算法,通过优先搜索强关联性的特征,找到两个域名之间关联性最强的关系链,方便解释说明。也就是说这是一套可解释的系统。
特殊页面分析
在对源码相似度极高的域名做人工排查的时候,我们发现我们爬取到了一些黑产的 sitemap 共 267 个,其中我们发现包含在同个 sitemap 内的域名极大概率是属于同个黑产家族。
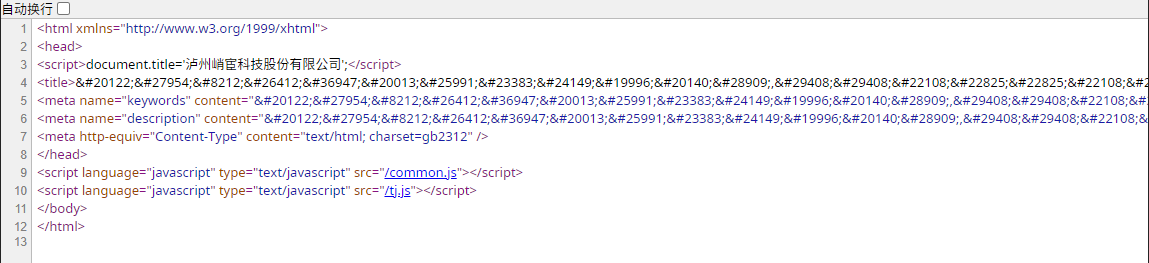
其次我们还发现了大量和下图结构雷同的网站源码,这里面只链接两个 js 文件,tj.js 负责加载网站统计链接,common.js 负责网页跳转功能。经过观察,我们发现该类网站跳转的目的地在一天之内经常会发生变动,并且目的域名覆盖了大量的黑产家族,我们怀疑这些网站可能是某个主营引流的黑产家族所负责的,负责将访问网站的用户引流到其他各个黑产中,并向其他黑产收取费用牟利。这侧面说明了靠动态渲染的结果进行关联的局限性。
黑产规模分析
我们根据域名访问量、排名等数据,对被找出的 17 个黑产团伙进行了规模分析。
| 家族编号 | 家族大小 | Rank in 1000w | Rank in 100w | Rank in 10w | Rank in 1w | Top rank | Top rank domain | 总请求数 | A记录请求数 | CNAME记录请求数 | 客户端数量 | 子域名数量 | 家族代表 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 444 | 2386 | 1472 | 53 | 4 | 0 | 50107 | 1818**.net | 3495347 | 1872520 | 515 | 1217811 | 118290 | jnw***.com |
| 14 | 519 | 44 | 12 | 1 | 0 | 93538 | 201yi***.com | 2120399 | 1361313 | 25 | 831320 | 2303 | 43***.com |
| 836 | 453 | 150 | 31 | 0 | 0 | 102151 | hk7***.com | 740461 | 396057 | 62 | 313256 | 5533 | 59***.com |
| 1611 | 1621 | 43 | 2 | 0 | 0 | 134438 | fff***.com | 323245 | 210272 | 15 | 18322 | 2464 | a8***.com |
| 2426 | 380 | 145 | 18 | 0 | 0 | 137519 | 722***.com | 298162 | 209548 | 136 | 93850 | 7305 | 339033***.com |
| 116 | 1146 | 96 | 5 | 0 | 0 | 301688 | cja***.com | 293039 | 164512 | 83 | 138275 | 5862 | gunnaram***.com |
| 952 | 1161 | 45 | 4 | 0 | 0 | 739550 | 31***.com | 243057 | 204190 | 18 | 47274 | 1719 | www422***.com |
| 2423 | 605 | 219 | 7 | 0 | 0 | 231843 | 7ee***.app | 197016 | 99839 | 2 | 66316 | 32193 | mm9***.app |
| 1680 | 656 | 52 | 0 | 0 | 0 | 1036293 | iyudshdeiaxk***.app | 138279 | 111034 | 29 | 33564 | 2465 | 583***.com |
| 279 | 635 | 201 | 3 | 0 | 0 | 269112 | s***.net | 79359 | 62019 | 766 | 12652 | 24878 | xyua***.com |
| 2943 | 937 | 21 | 1 | 0 | 0 | 505357 | k3***.com | 78718 | 51315 | 0 | 26073 | 738 | b83***.com |
| 2425 | 380 | 85 | 10 | 0 | 0 | 354192 | uut***.com | 45830 | 36816 | 72 | 18308 | 1195 | yxh***.com |
| 603 | 593 | 80 | 0 | 0 | 0 | 1296846 | yout***.com | 45286 | 36425 | 57 | 6546 | 1681 | trade***.cn |
| 809 | 239 | 21 | 4 | 0 | 0 | 455885 | efma***.cn | 21970 | 11707 | 29 | 9255 | 511 | fa-ya***.com |
| 953 | 308 | 34 | 0 | 0 | 0 | 1191366 | xxld***.com | 9281 | 5650 | 46 | 709 | 856 | grin***.com |
| 1668 | 357 | 10 | 1 | 0 | 0 | 650306 | fanyacha***.com | 2602 | 1936 | 5 | 664 | 724 | 9***.com |
| 1754 | 1497 | 2 | 0 | 0 | 0 | 5760392 | yxb***.com | 1985 | 1413 | 0 | 1322 | 46 | 4444***.com |
域名数量上千的家族共有 5 个,看似都是规模庞大的黑产家族,但假如只考虑排名小于一千万的域名的话,444 号家族仍有超过一半的域名低于该排名分界线,其余家族只有不到 100 个域名,个别家族甚至只有两个域名(1754 号家族)。可见,域名数量多并不能说明该黑产团伙拥有较大的规模。
从总请求数可以看出编号为 444 和 14 的家族是两个规模比较大的黑产家族,其一个月的总请求数大概在百万级别,客户端数量也在十万级别,域名的最高排名也都在 10w 以内。
总结与展望
本质上,寻找黑产团伙的任务就是要找到各种可能的共同特征点进行聚类。我们希望用尽可能少的人工干预和尽可能简单的算法,来完成黑产团伙挖掘的工作,用最少的工作量和最简单的思路完成同样的事情。
我们觉得从源码结构相似性入手是一个正确的思路,虽然不同黑产家族之间可能使用同一套模板,同一个黑产也可能使用不同的模板,但就实际情况来看,使用同一套模板的不同黑产家族也会对模板进行修改,不会直接照搬使用,而同一个黑产使用不同模板的情况也可以结合其他特征进行关联。从源码结构相似性入手不仅准确性有保障,也节省了大量需要人工处理的工作量,同时效率也特别优秀,不失为一种好的预处理思路。
原文始发于王, 欣蕾:DataCon2021优秀解题思路分享:域名体系安全(清华大学-叽里呱啦)